Section 26 Least Squares Approximations
Focus Questions
By the end of this section, you should be able to give precise and thorough answers to the questions listed below. You may want to keep these questions in mind to focus your thoughts as you complete the section.
How, in general, can we find a least squares approximation to a system \(A \vx = \vb\text{?}\)
If the columns of \(A\) are linearly independent, how can we find a least squares approximation to \(A \vx = \vb\) using just matrix operations?
Why are these approximations called “least squares” approximations?
Subsection Application: Fitting Functions to Data
Data is all around us. Data is collected on almost everything and it is important to be able to use data to make predictions. However, data is rarely well-behaved and so we generally need to use approximation techniques to estimate from the data. One technique for this is least squares approximations. As we will see, we can use linear algebra to fit a variety of different types of curves to data.
Subsection Introduction
In this section our focus is on fitting linear and polynomial functions to data sets.
Preview Activity 26.1.
NBC was awarded the U.S. television broadcast rights to the 2016 and 2020 summer Olympic games. Table 26.1 lists the amounts paid (in millions of dollars) by NBC sports for the 2008 through 2012 summer Olympics plus the recently concluded bidding for the 2016 and 2020 Olympics, where year 0 is the year 2008. (We will assume a simple model here, ignoring variations such as value of money due to inflation, viewership data which might affect NBC's expected revenue, etc.) Figure 26.2 shows a plot of the data. Our goal in this activity is to find a linear function \(f\) defined by \(f(x) = a_0 + a_1x\) that fits the data well.
| Year | Amount |
| 0 | 894 |
| 4 | 1180 |
| 8 | 1226 |
| 12 | 1418 |

If the data were actually linear, then the data would satisfy the system
The vector form of this equation is
This equation does not have a solution, so we seek the best approximation to a solution we can find. That is, we want to find \(a_0\) and \(a_1\) so that the line \(f(x) = a_0+a_1x\) provides a best fit to the data.
Letting \(\vv_1 = [1 \ 1 \ 1 \ 1]^{\tr}\) and \(\vv_2 = [0 \ 4 \ 8 \ 12]^{\tr}\text{,}\) and \(\vb = [894 \ 1180 \ 1226 \ 1418]^{\tr}\text{,}\) our vector equation becomes
To make a best fit, we will minimize the square of the distance between \(\vb\) and a vector of the form \(a_0\vv_1 + a_1 \vv_2\text{.}\) That is, minimize
Rephrasing this in terms of projections, we are looking for the vector in \(W = \Span\{\vv_1, \vv_2\}\) that is closest to \(\vb\text{.}\) In other words, the values of \(a_0\) and \(a_1\) will occur as the weights when we write \(\proj_{W} \vb\) as a linear combination of \(\vv_1\) and \(\vv_2\text{.}\) The one wrinkle in this problem is that we need an orthogonal basis for \(W\) to find this projection. Use appropriate technology throughout this activity.
(a)
Find an orthogonal basis \(\CB = \{\vw_1, \vw_2\}\) for \(W\text{.}\)
(b)
Use the basis \(\CB\) to find \(\vy = \proj_{W} \vb\) as illustrated in Figure 26.3.

(c)
Find the values of \(a_0\) and \(a_1\) that give our best fit line by writing \(\vy\) as a linear combination of \(\vv_1\) and \(\vv_2\text{.}\)
(d)
Draw a picture of your line from the previous part on the axes with the data set. How well do you think your line approximates the data? Explain.
Subsection Least Squares Approximations
In Section 25 we saw that the projection of a vector \(\vv\) in \(\R^n\) onto a subspace \(W\) of \(\R^n\) is the best approximation to \(\vv\) of all the vectors in \(W\text{.}\) In fact, if \(\vv = [v_1 \ v_2 \ \ldots \ v_n]^{\tr}\) and \(\proj_W \vv = [w_1 \ w_2 \ w_3 \ \ldots \ w_m]^{\tr}\text{,}\) then the error in approximating \(\vv\) by \(\vw\) is given by
In the context of Preview Activity 26.1, we projected the vector \(\vb\) onto the span of the vectors \(\vv_1 = [1 \ 1 \ 1 \ 1]^{\tr}\) and \(\vv_2 = [0 \ 4 \ 8 \ 12]^{\tr}\text{.}\) The projection minimizes the distance between the vectors in \(W\) and the vector \(\vb\) (as shown in Figure 26.3), and also produces a line which minimizes the sums of the squares of the vertical distances from the line to the data set as illustrated in Figure 26.4 with the olympics data. This is why these approximations are called least squares approximations.

While we can always solve least squares problems using projections, we can often avoid having to create an orthogonal basis when fitting functions to data. We work in a more general setting, showing how to fit a polynomial of degree \(n\) to a set of data points. Our goal is to fit a polynomial \(p(x) = a_0+a_1x+a_2x^2+ \cdots + a_nx^n\) of degree \(n\) to \(m\) data points \((x_1,y_1)\text{,}\) \((x_2,y_2)\text{,}\) \(\ldots\text{,}\) \((x_m,y_m)\text{,}\) no two of which have the same \(x\) coordinate. In the unlikely event that the polynomial \(p(x)\) actually passes through the \(m\) points, then we would have the \(m\) equations
in the \(n+1\) unknowns \(a_0\text{,}\) \(a_1\text{,}\) \(\ldots\text{,}\) \(a_{n-1}\text{,}\) and \(a_n\text{.}\)
The \(m\) data points are known in this situation and the coefficients \(a_0\text{,}\) \(a_1\text{,}\) \(\ldots\text{,}\) \(a_n\) are the unknowns. To write the system in matrix-vector form, the coefficient matrix \(M\) is
while the vectors \(\va\) and \(\vy\) are
Letting \(\vy = [y_1 \ y_2 \ \ldots \ y_m]^{\tr}\) and \(\vv_i = [x_1^{i-1} \ x_2^{i-1} \ \ldots \ x_m^{i-1}]^{\tr}\) for \(1 \leq i \leq n+1\text{,}\) the vector form of the system is
Of course, it is unlikely that the \(m\) data points already lie on a polynomial of degree \(n\text{,}\) so the system will usually have no solution. So instead of attempting to find coefficients \(a_0\text{,}\) \(a_1\text{,}\) \(\ldots\text{,}\) \(a_n\) that give a solution to this system, which may be impossible, we instead look for a vector that is ``close" to a solution. As we have seen, the vector \(\proj_{W} \vy\text{,}\) where \(W\) is the span of the columns of \(M\text{,}\) minimizes the sum of the squares of the differences of the components. That is, our desired approximation to a solution to \(M \vx = \vy\) is the projection of \(\vy\) onto \(\Col M\text{.}\) Now \(\proj_W \vy\) is a linear combination of the columns of \(M\text{,}\) so \(\proj_W \vy = M \va^*\) for some vector \(\va^*\text{.}\) This vector \(\va^*\) then minimizes \(|| \proj_{\perp W} \vy|| = ||\vy - M \va ||\text{.}\) That is, if we let \((M\va)^{\tr} = [b_1 \ b_2 \ b_3 \ \cdots \ b_m]\text{,}\) we are minimizing
The expression \(||\vy - M\va||^2\) measures the error in our approximation.
The question we want to answer is how we can find the vector \(\va^*\) that minimizes \(||\vy -M\va||\) in a way that is more convenient than computing a projection. We answer this question in a general setting in the next activity.
Activity 26.2.
Let \(A\) be an \(m \times n\) matrix and let \(\vb\) be in \(\R^m\text{.}\) Let \(W = \Col A\text{.}\) Then \(\proj_W \vb\) is in \(\Col A\text{,}\) so let \(\vx^*\) be in \(\R^{n}\) such that \(A\vx^* = \proj_W \vb\text{.}\)
(a)
Explain why \(\vb - A\vx^*\) is orthogonal to every vector of the form \(A\vx\text{,}\) for any \(\vx\) in \(\R^{n}\text{.}\) That is, \(\vb - A\vx^*\) is orthogonal to \(\Col A\text{.}\)
(b)
Let \(\va_i\) be the \(i\)th column of \(A\text{.}\) Explain why \(\va_i \cdot \left(\vb - A\vx^*\right) = 0\text{.}\) From this, explain why \(A^{\tr}\left(\vb - A\vx^*\right) = 0\text{.}\)
(c)
From the previous part, show that \(\vx^*\) satisfies the equation
The result of Activity 26.2 is that we can now do least squares polynomial approximations with just matrix operations. We summarize this in the following theorem.
Theorem 26.5.
The least squares solutions to the system \(A \vx = \vb\) are the solutions to the corresponding system
The equations in the system (26.8) are called the normal equations for \(A \vx = \vb\text{.}\) To illustrate, with the Olympics data, our data points are \((0, 894)\text{,}\) \((4, 1180)\text{,}\) \((8, 1226)\text{,}\) \((12,1418)\) with \(\vy = [894 \ 1180 \ 1226 \ 1418]^{\tr}\text{.}\) So \(M = \left[ \begin{array}{cc} 1\amp0 \\ 1\amp4 \\ 1\amp8 \\ 1\amp12 \end{array} \right]\text{.}\) Notice that \(M^{\tr}M\) is invertible, to find the degree 1 approximation to the data, technology shows that
just as in Preview Activity 26.1.
Activity 26.3.
Now use the least squares method to find the best polynomial approximations (in the least squares sense) of degrees 2 and 3 for the Olympics data set in Table 26.1. Which polynomial seems to give the “best” fit? Explain why. Include a discussion of the errors in your approximations. Use your “best” least squares approximation to estimate how much NBC might pay for the television rights to the 2024 Olympic games. Use technology as appropriate.
The solution with our Olympics data gave us the situation where \(M^{\tr}M\) was invertible. This corresponded to a unique least squares solution \(\left(M^{\tr}M\right)^{-1}M^{\tr}\vy\text{.}\) It is reasonable to ask when this happens in general. To conclude this section, we will demonstrate that if the columns of a matrix \(A\) are linearly independent, then \(A^{\tr}A\) is invertible.
Activity 26.4.
Let \(A\) be an \(m \times n\) matrix with linearly independent columns.
(a)
What must be the relationship between \(m\) and \(n\text{?}\) Explain.
(b)
We know that an \(n \times n\) matrix \(M\) is invertible if and only if the only solution to the homogeneous system \(M \vx = \vzero\) is \(\vx = \vzero\text{.}\) Note that \(A^{\tr}A\) is an \(n \times n\) matrix. Suppose that \(A^{\tr}A \vx = \vzero\) for some \(\vx\) in \(\R^n\text{.}\)
(i)
Show that \(||A\vx|| = 0\text{.}\)
What is \(\vx^{\tr} (A^{\tr}A \vx)\text{?}\)
(ii)
What does \(||A\vx|| = 0\) tell us about \(\vx\) in relation to \(\Nul A\text{?}\) Why?
(iii)
What is \(\Nul A\text{?}\) Why? What does this tell us about \(\vx\) and then about \(A^{\tr}A\text{?}\)
We summarize the result of Activity 26.4 in the following theorem.
Theorem 26.6.
If the columns of \(A\) are linearly independent, then the least squares solution \(\vx^*\) to the system \(A \vx = \vb\) is
If the columns of \(A\) are linearly dependent, we can still solve the normal equations, but will obtain more than one solution. In a later section we will see that we can also use a pseudoinverse in these situations.
Subsection Examples
What follows are worked examples that use the concepts from this section.
Example 26.7.
According to the Centers for Disease Control and Prevention 45 , the average length of a male infant (in centimeters) in the US as it ages (with time in months from 1.5 to 8.5) is given in Table 26.8.
| Age (months) | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 |
| Average Length (cm) | 56.6 | 59.6 | 62.1 | 64.2 | 66.1 | 67.9 | 69.5 | 70.9 |
In this problem we will find the line and the quadratic of best fit in the least squares sense to this data. We treat age in months as the independent variable and length in centimeters as the dependent variable.
(a)
Find a line that is the best fit to the data in the least squares sense. Draw a picture of your least squares solution against a scatterplot of the data.
Solution.
We assume that a line of the form \(f(x) = a_1x+a_0\) contains all of the data points. The first data point would satisfy \(1.5a_1+a_0 = 56.6\text{,}\) the second \(2.5a_1+a_0 = 59.6\text{,}\) and so on, giving us the linear system
Letting
we can write this system in the matrix form \(A \vx = \vb\text{.}\) Neither column of \(A\) is a multiple of the other, so the columns of \(A\) are linearly independent. The least squares solution \(\vx^*\) to the system is then found by
Technology shows that (with entries rounded to 3 decimal places), \(\left(A^{\tr}A\right)^{-1}A^{\tr}\) is
and
So the least squares linear function to the data is \(f(x) \approx 2.011x + 54.559\text{.}\) A graph of \(f\) against the data points is shown at left in Figure 26.9. 
(b)
Now find the least squares quadratic of the form \(q(x) = a_2x^2+a_1x+a_0\) to the data. Draw a picture of your least squares solution against a scatterplot of the data.
Solution.
The first data point would satisfy \((1.5^2)a_2+1.5a_1+a_0 = 56.6\text{,}\) the second \((2.5)^2a_2+2.5a_1+a_0 = 59.6\text{,}\) and so on, giving us the linear system
Letting
we can write this system in the matrix form \(A \vx = \vb\text{.}\) Technology shows that every column of the reduced row echelon form of \(A\) contains a pivot, so the columns of \(A\) are linearly independent. The least squares solution \(\vx^*\) to the system is then found by
Technology shows that (with entries rounded to 3 decimal places) \(\left(A^{\tr}A\right)^{-1}\) is
and
So the least squares quadratic function to the data is \(q\) defined by \(q(x) \approx -0.118x^2+3.195x + 52.219\text{.}\) A graph of \(q\) against the data points is shown at right in Figure 26.9.
Example 26.10.
Least squares solutions can be found through a QR factorization, as we explore in this example. Let \(A\) be an \(m \times n\) matrix with linearly independent columns and QR factorization \(A = QR\text{.}\) Suppose that \(\vb\) is not in \(\Col A\) so that the system \(A \vx = \vb\) is inconsistent. We know that the least squares solution \(\vx^*\) to \(A \vx = \vb\) is
(a)
Replace \(A\) by its QR factorization in (26.9) to show that
Hint.
Use the fact that \(Q\) is orthogonal and \(R\) is invertible.
Solution.
Replacing \(A\) with \(QR\) and using the fact that \(R\) is invertible and \(Q\) is orthogonal to see that
So if \(A = QR\) is a QR factorization of \(A\text{,}\) then the least squares solution to \(A \vx = \vb\) is \(R^{-1}Q^{\tr} \vb\text{.}\)
(b)
Consider the data set in Table 26.11, which shows the average life expectance in years in the US for selected years from 1950 to 2010.
| year | 1950 | 1965 | 1980 | 1995 | 2010 |
| age | 68.14 | 70.21 | 73.70 | 75.98 | 78.49 |
(i)
Use (26.9) to find the least squares linear fit to the data set.
Solution.
A linear fit to the data will be provided by the least squares solution to \(A \vx = \vb\text{,}\) where
Technology shows that
(ii)
Use appropriate technology to find the QR factorization of an appropriate matrix \(A\text{,}\) and use the QR decomposition to find the least squares linear fit to the data. Compare to what you found in part i.
Solution.
Technology shows that \(A = QR\text{,}\) where
Then we have that
just as in part i.
Subsection Summary
A least squares approximation to \(A \vx = \vb\) is found by orthogonally projecting \(\vb\) onto \(\Col A\text{.}\)
If the columns of \(A\) are linearly independent, then the least squares approximation to \(A \vx = \vb\) is \(\left(A^{\tr}A\right)^{-1}A^{\tr} \vb\text{.}\)
-
The least squares solution to \(A \vx = \vb\text{,}\) where \(A\vx = [y_1 \ y_2 \ \ldots \ y_m]\) and \(\vb = [b_1 \ b_2 \ \ldots \ b_ m]^{\tr}\text{,}\) minimizes the distance \(||A\vx - \vb||\text{,}\) where
\begin{equation*} ||A\vx - \vb||^2 = (y_1-b_1)^2 + (y_2-b_2)^2 + \cdots + (y_m-b_m)^2\text{.} \end{equation*}So the least squares solution minimizes a sum of squares.
Exercises Exercises
1.
The University of Denver Infant Study Center investigated whether babies take longer to learn to crawl in cold months, when they are often bundled in clothes that restrict their movement, than in warmer months. The study sought a relationship between babies' first crawling age and the average temperature during the month they first try to crawl (about 6 months after birth). Some of the data from the study is in Table 26.12. Let \(x\) represent the temperature in degrees Fahrenheit and \(C(x)\) the average crawling age in months.
| \(x\) | 33 | 37 | 48 | 57 |
| \(C(x)\) | 33.83 | 33.35 | 33.38 | 32.32 |
(a)
Find the least squares line to fit this data. Plot the data and your line on the same set of axes. (We aren't concerned about whether a linear fit is really a good choice outside of this data set, we just fit a line to it to see what happens.)
(b)
Use your least squares line to predict the average crawling age when the temperature is 65.
2.
The cost, in cents, of a first class postage stamp in years from 1981 to 1995 is shown in Table 26.13.
| Year | 1981 | 1985 | 1988 | 1991 | 1995 |
| Cost | 20 | 22 | 25 | 29 | 32 |
(a)
Find the least squares line to fit this data. Plot the data and your line on the same set of axes.
(b)
Now find the least squares quadratic approximation to this data. Plot the quadratic function on same axes as your linear function.
(c)
Use your least squares line and quadratic to predict the cost of a postage stamp in this year. Look up the cost of a stamp today and determine how accurate your prediction is. Which function gives a better approximation? Provide reasons for any discrepancies.
3.
According to The Song of Insects by G.W. Pierce (Harvard College Press, 1948) the sound of striped ground crickets chirping, in number of chirps per second, is related to the temperature. So the number of chirps per second could be a predictor of temperature. The data Pierce collected is shown in the table and scatterplot below, where \(x\) is the (average) number of chirps per second and \(y\) is the temperature in degrees Fahrenheit.
| \(x\) | \(y\) |
| 20.0 | 88.6 |
| 16.0 | 71.6 |
| 19.8 | 93.3 |
| 18.4 | 84.3 |
| 17.1 | 80.6 |
| 15.5 | 75.2 |
| 14.7 | 69.7 |
| 17.1 | 82.0 |
| 15.4 | 69.4 |
| 16.2 | 83.3 |
| 15.0 | 79.6 |
| 17.2 | 82.6 |
| 16.0 | 80.6 |
| 17.0 | 83.5 |
| 14.4 | 76.3 |

The relationship between \(x\) and \(y\) is not exactly linear, but looks to have a linear pattern. It could be that the relationship is really linear but experimental error causes the data to be slightly inaccurate. Or perhaps the data is not linear, but only approximately linear. Find the least squares linear approximation to the data.
4.
We showed that if the columns of \(A\) are linearly independent, then \(A^{\tr}A\) is invertible. Show that the reverse implication is also true. That is, show that if \(A^{\tr}A\) is invertible, then the columns of \(A\) are linearly independent.
5.
Consider the small data set of points \(S = \{(2,1), (2,2), (2,3)\}\text{.}\)
(a)
Find a linear system \(A \vx = \vb\) whose solution would define a least squares linear approximation to the data in set \(S\text{.}\)
(b)
Explain what happens when we attempt to find the least squares solution \(\vx^*\) using the matrix \(\left(A^{\tr}A\right)^{-1}A^{\tr}\text{.}\) Why does this happen?
(c)
Does the system \(A \vx = \vb\) have a least squares solution? If so, how many and what are they? If not, why not?
(d)
Fit a linear function of the form \(x = a_0 + a_1y\) to the data. Why should you have expected the answer?
6.
Let \(M\) and \(N\) be any matrices such that \(MN\) is defined. In this exercise we investigate relationships between ranks of various matrices.
(a)
Show that \(\Col MN\) is a subspace of \(\Col M\text{.}\) Use this result to explain why \(\rank(MN) \leq \rank(M)\text{.}\)
(b)
Show that \(\rank\left(M^{\tr}M\right) = \rank(M) = \rank\left(M^{\tr}\right)\text{.}\)
For part, see Exercise 12 in Section 15.
(c)
Show that \(\rank(MN) \leq \min\{\rank(M), \rank(N)\}\text{.}\)
7.
We have seen that if the columns of a matrix \(M\) are linearly independent, then
is a least squares solution to \(M \va = \vy\text{.}\) What if the columns of \(M\) are linearly dependent? From Activity 26.1, a least squares solution to \(M \va = \vy\) is a solution to the equation \(\left(M^{\tr}M\right)\va = M^{\tr}\vy\text{.}\) In this exercise we demonstrate that \(\left(M^{\tr}M\right)\va = M^{\tr}\vy\) always has a solution.
(a)
Explain why it is enough to show that the rank of the augmented matrix \([M^{\tr}M \ | \ M^{\tr}\vy]\) is the same as the rank of \(M^{\tr}M\text{.}\)
(b)
Explain why \(\rank\left([M^{\tr}M \ | \ M^{\tr}\vy]\right) \geq \rank(M)\text{.}\)
See Exercise 6.
(c)
Explain why \([M^{\tr}M \ | \ M^{\tr}\vy] = M^{\tr}[M \ | \ \vy]\text{.}\)
Use the definition of the matrix product.
(d)
Explain why \(\rank\left([M^{\tr}M \ | \ M^{\tr}\vy]\right) \leq \rank\left(M^{\tr} \right)\text{.}\)
See Exercise 6.
(e)
Finally, explain why \(\rank\left([M^{\tr}M \ | \ M^{\tr}\vy]\right) = \rank\left(M^{\tr}M\right)\text{.}\)
Combine parts (b) and (d).
8.
If \(A\) is an \(m \times n\) matrix with linearly independent columns, the least squares solution \(\vx^* = \left(A^{\tr}A\right)^{-1}A^{\tr} \vb\) to \(A \vx = \vb\) has the property that \(A \vx^* = A\left(A^{\tr}A\right)^{-1}A^{\tr} \vb\) is the vector in \(\Col A\) that is closest to \(\vb\text{.}\) That is, \(A\left(A^{\tr}A\right)^{-1}A^{\tr} \vb\) is the projection of \(\vb\) onto \(\Col A\text{.}\) The matrix \(P = A\left(A^{\tr}A\right)^{-1}A^{\tr}\) is called a projection matrix. Projection matrices have special properties.
(a)
Show that \(P^2 = P = P^{\tr}\text{.}\)
(b)
In general, we define projection matrices as follows. A square matrix \(E\) is a projection matrix if \(E^2 = E\text{.}\)
Definition 26.14.
(c)
Notice that the projection matrix from part (b) is not an orthogonal matrix. A square matrix \(E\) is a orthogonal projection matrix if \(E^2 = E = E^{\tr}\text{.}\)
Definition 26.15.
(d)
If \(E\) is an \(n \times n\) orthogonal projection matrix, show that if \(\vb\) is in \(\R^n\text{,}\) then \(\vb - E\vb\) is orthogonal to every vector in \(\Col E\text{.}\) (Hence, \(E\) projects orthogonally onto \(\Col E\text{.}\))
(e)
Recall the projection \(\proj_{\vv} \vu\) of a vector \(\vu\) in the direction of a vector \(\vv\) is give by \(\proj_{\vv} \vu = \frac{\vu \cdot \vv}{\vv \cdot \vv} \vv\text{.}\) Show that \(\proj_{\vv} \vu = E\vu\text{,}\) where \(E\) is the orthogonal projection matrix \(\frac{1}{\vv \cdot \vv} \left(\vv \vv^{\tr} \right)\text{.}\) Illustrate with \(\vv = [1 \ 1]^{\tr}\text{.}\)
9.
Label each of the following statements as True or False. Provide justification for your response.
(a) True/False.
If the columns of \(A\) are linearly independent, then there is a unique least squares solution to \(A\vx = \vb\text{.}\)
(b) True/False.
Let \(\{\vv_1, \vv_2, \ldots, \vv_n\}\) be an orthonormal basis for \(\R^n\text{.}\) The least squares solution to \([\vv_1 \ \vv_2 \ \cdots \ \vv_{n-1}] \vx = \vv_n\) is \(\vx = \vzero\text{.}\)
(c) True/False.
The least squares line to the data points \((0,0)\text{,}\) \((1,0)\text{,}\) and \((0,1)\) is \(y=x\text{.}\)
(d) True/False.
If the columns of a matrix \(A\) are not invertible and the vector \(\vb\) is not in \(\Col A\text{,}\) then there is no least squares solution to \(A \vx = \vb\text{.}\)
(e) True/False.
Every matrix equation of the form \(A \vx = \vb\) has a least squares solution.
(f) True/False.
If the columns of \(A\) are linearly independent, then the least squares solution to \(A \vx = \vb\) is the orthogonal projection of \(\vb\) onto \(\Col A\text{.}\)
Subsection Project: Other Least Squares Approximations
In this section we learned how to fit a polynomial function to a set of data in the least squares sense. But data takes on many forms, so it is important to be able to fit other types of functions to data sets. We investigate three different types of regression problems in this project.
Project Activity 26.5.
The length of a species of fish is to be represented as a function of the age and water temperature as shown in the table on the next page. 47 The fish are kept in tanks at 25, 27, 29 and 31 degrees Celsius. After birth, a test specimen is chosen at random every 14 days and its length measured. The data include:
\(I\text{,}\) the index;
\(x\text{,}\) the age of the fish in days;
\(y\text{,}\) the water temperature in degrees Celsius;
\(z\text{,}\) the length of the fish.
Since there are three variables in the data, we cannot perform a simple linear regression. Instead, we seek a model of the form
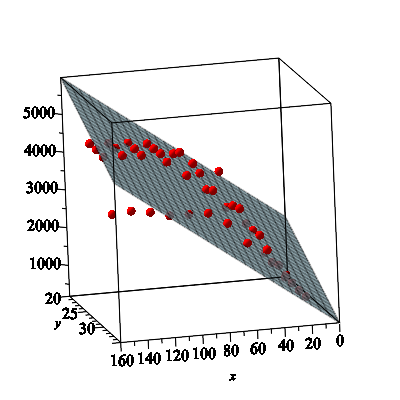
to fit the data, where \(f(x,y)\) approximates the length. That is, we seek the best fit plane to the data. This is an example of what is called multiple linear regression. A scatterplot of the data, along with the best fit plane, is also shown.
(a)
As we did when we fit polynomials to data, we start by considering what would happen if all of our data points satisfied our model function. In this case our data points have the form \((x_1,y_1,z_1)\text{,}\) \((x_2,y_2,z_2)\text{,}\) \(\ldots\text{,}\) \((x_m,y_m,z_m)\text{.}\) Explain what system of linear equations would result if the data points actually satisfy our model function \(f(x,y)= ax+by+c\text{.}\) (You don't need to write 44 different equations, just explain the general form of the system.)
(b)
Write the system from (a) in the form \(M \va = \vz\text{,}\) and specifically identify the matrix \(M\) and the vectors \(\va\) and \(\vz\text{.}\)
(c)
The same derivation as with the polynomial regression models shows that the vector \(\va^*\) that minimizes \(||\vz - M\va||\) is found by
Use this to find the least squares fit of the form \(f(x,y) = ax+by+c\) to the data.
(d)
Provide a numeric measure of how well this model function fits the data. Explain.
| Index | Age | Temp (\(^\circ\)C) | Length |
| 1 | 14 | 25 | 620 |
| 2 | 28 | 25 | 1315 |
| 3 | 41 | 25 | 2120 |
| 4 | 55 | 25 | 2600 |
| 5 | 69 | 25 | 3110 |
| 6 | 83 | 25 | 3535 |
| 7 | 97 | 25 | 3935 |
| 8 | 111 | 25 | 4465 |
| 9 | 125 | 25 | 4530 |
| 10 | 139 | 25 | 4570 |
| 11 | 153 | 25 | 4600 |
| 12 | 14 | 27 | 625 |
| 13 | 28 | 27 | 1215 |
| 14 | 41 | 27 | 2110 |
| 15 | 55 | 27 | 2805 |
| 16 | 69 | 27 | 3255 |
| 17 | 83 | 27 | 4015 |
| 18 | 97 | 27 | 4315 |
| 19 | 111 | 27 | 4495 |
| 20 | 125 | 27 | 4535 |
| 21 | 139 | 27 | 4600 |
| 22 | 153 | 27 | 4600 |
| 23 | 14 | 29 | 590 |
| 24 | 28 | 29 | 1305 |
| 25 | 41 | 29 | 2140 |
| 26 | 55 | 29 | 2890 |
| 27 | 69 | 29 | 3920 |
| 28 | 83 | 29 | 3920 |
| 29 | 97 | 29 | 4515 |
| 30 | 111 | 29 | 4520 |
| 31 | 125 | 29 | 4525 |
| 32 | 139 | 29 | 4565 |
| 33 | 153 | 29 | 4566 |
| 34 | 14 | 31 | 590 |
| 35 | 28 | 31 | 1205 |
| 36 | 41 | 31 | 1915 |
| 37 | 55 | 31 | 2140 |
| 38 | 69 | 31 | 2710 |
| 39 | 83 | 31 | 3020 |
| 40 | 97 | 31 | 3030 |
| 41 | 111 | 31 | 3040 |
| 42 | 125 | 31 | 3180 |
| 43 | 139 | 31 | 3257 |
| 44 | 153 | 31 | 3214 |
Project Activity 26.6.
Population growth is typically not well modeled by polynomial functions. Populations tend to grow at rates proportional to the population, which implies exponential growth. For example, Table 26.16 shows the approximate population of the United States in years between 1920 and 2000, with the population measured in millions.
| Year | 1920 | 1930 | 1940 | 1950 | 1960 | 1970 | 1980 | 1990 | 2000 |
| Population | 106 | 123 | 142 | 161 | 189 | 213 | 237 | 259 | 291 |
If we assume the population grows exponentially, we would want to find the best fit function \(f\) of the form \(f(t) = ae^{kt}\text{,}\) where \(a\) and \(k\) are constants. However, an exponential function is not linear. So to apply the methods we have developed, we could instead apply the natural logarithm to both sides of \(y = ae^{kt}\) to obtain the equation \(\ln(y) = \ln(a) + kt\text{.}\) We can then find the best fit line to the data in the form \((t, \ln(y))\) to determine the values of \(\ln(a)\) and \(k\text{.}\) Use this approach to find the best fit exponential function in the least squares sense to the U.S. population data. Then look up the U.S. population in 2010 (include your source) and compare to the estimate given by your model function. If your prediction is not very close, give some plausible explanations for the difference.

Project Activity 26.7.
Carl Friedrich Gauss is often credited with inventing the method of least squares. He used the method to find a best-fit ellipse which allowed him to correctly predict the orbit of the asteroid Ceres as it passed behind the sun in 1801. (Adrien-Marie Legendre appears to be the first to publish the method, though.) Here we examine the problem of fitting an ellipse to data.
An ellipse is a quadratic equation that can be written in the form
for constants \(B\text{,}\) \(C\text{,}\) \(D\text{,}\) \(E\text{,}\) and \(F\text{,}\) with \(B > 0\text{.}\) We will find the best-fit ellipse in the least squares sense through the points
A picture of the best fit ellipse is shown in Figure 26.17.
(a)
Find the system of linear equations that would result if the ellipse (26.10) were to exactly pass through the given points.
(b)
Write the linear system from part (a) in the form \(A \vx = \vb\text{,}\) where the vector \(\vx\) contains the unknowns in the system. Clearly identify \(A\text{,}\) \(\vx\text{,}\) and \(\vb\text{.}\)
(c)
Find the least squares ellipse to this set of points. Make sure your method is clear. (Note that we are really fitting a surface of the form \(f(x,y) = x^2 + By^2 + Cxy + Dx + Ey + F\) to a set of data points in the \(xy\)-plane. So the error is the sum of the vertical distances from the points in the \(xy\)-plane to the surface.)
cdc.gov/growthcharts/html_charts/lenageinf.htmmacrotrends.net/countries/USA/united-states/life-expectancy