Section 30 Using the Singular Value Decomposition
Focus Questions
By the end of this section, you should be able to give precise and thorough answers to the questions listed below. You may want to keep these questions in mind to focus your thoughts as you complete the section.
What is the condition number of a matrix and what does it tell us about the matrix?
What is the pseudoinverse of a matrix?
Why are pseudoinverses useful?
How does the pseudoinverse of a matrix allow us to find least squares solutions to linear systems?
Subsection Application: Global Positioning System
You are probably familiar with the Global Positioning System (GPS). The system allows anyone with the appropriate software to accurately determine their location at any time. The applications are almost endless, including getting real-time driving directions while in your car, guiding missiles, and providing distances on golf courses.
The GPS is a worldwide radio-navigation system owned by the US government and operated by the US Air Force. GPS is one of four global navigation satellite systems. At least twenty four GPS satellites orbit the Earth at an altitude of approximately 11,000 nautical miles. The satellites are placed so that at any time at least four of them can be accessed by a GPS receiver. Each satellite carries an atomic clock to relay a time stamp along with its position in space. There are five ground stations to coordinate and ensure that the system is working properly.
The system works by triangulation, but there is also error involved in the measurements that go into determining position. Later in this section we will see how the method of least squares can be used to determine the receiver's position.
Subsection Introduction
A singular value decomposition has many applications, and in this section we discuss how a singular value decomposition can be used in image compression, to determine how sensitive a matrix can be to rounding errors in the process of row reduction, and to solve least squares problems.
Subsection Image Compression
The digital age has brought many new opportunities for the collection, analysis, and dissemination of information. Along with these opportunities come new difficulties as well. All of this digital information must be stored in some way and be retrievable in an efficient manner. A singular value decomposition of digitally stored information can be used to compress the information or clean up corrupted information. In this section we will see how a singular value decomposition can be used in image compression. While a singular value decomposition is normally used with very large matrices, we will restrict ourselves to small examples so that we can more clearly see how a singular value decomposition is applied.
Preview Activity 30.1.
Let \(A = \frac{1}{4}\left[ \begin{array}{ccrr} 67\amp 29\amp -31\amp -73 \\ 29\amp 67\amp -73\amp -31 \\ 31\amp 73\amp -67\amp -29 \\ 73\amp 31\amp -29\amp -67 \end{array} \right]\text{.}\) A singular value decomposition for \(A\) is \(U \Sigma V^{\tr}\text{,}\) where
(a)
Write the summands in the corresponding outer product decomposition of \(A\text{.}\)
(b)
The outer product decomposition of \(A\) writes \(A\) as a sum of rank 1 matrices (the summands \(\sigma_i \vu_i \vv_i^{\tr})\text{.}\) Each summand contains some information about the matrix \(A\text{.}\) Since \(\sigma_1\) is the largest of the singular values, it is reasonable to expect that the summand \(A_1 = \sigma_1 \vu_1 \vv_1^{\tr}\) contains the most information about \(A\) among all of the summands. To get a measure of how much information \(A_1\) contains of \(A\text{,}\) we can think of \(A\) as simply a long vector in \(\R^{mn}\) where we have folded the data into a rectangular array (we will see later why taking the norm as the norm of the vector in \(\R^{nm}\) makes sense, but for now, just use this definition). If we are interested in determining the error in approximating an image by a compressed image, it makes sense to use the standard norm in \(\R^{mn}\) to determine length and distance, which is really just the Frobenius norm that comes from the Frobenius inner product defined by
where \(U = [u_{ij}]\) and \(V = [v_{ij}]\) are \(m \times n\) matrices. (That (30.1) defines an inner product on the set of all \(n \times n\) matrices is left to discuss in a later section.) So in this section all the norms for matrices will refer to the Frobenius norm. Rather than computing the distance between \(A_1\) and \(A\) to measure the error, we are more interested in the relative error
(i)
Calculate the relative error in approximating \(A\) by \(A_1\text{.}\) What does this tell us about how much information \(A_1\) contains about \(A\text{?}\)
(ii)
Let \(A_2 = \sum_{k=1}^2 \sigma_k \vu_k \vv_k^{\tr}\text{.}\) Calculate the relative error in approximating \(A\) by \(A_2\text{.}\) What does this tell us about how much information \(A_2\) contains about \(A\text{?}\)
(iii)
Let \(A_3 = \sum_{k=1}^3 \sigma_k \vu_k \vv_k^{\tr}\text{.}\) Calculate the relative error in approximating \(A\) by \(A_3\text{.}\) What does this tell us about how much information \(A_3\) contains about \(A\text{?}\)
(iv)
Let \(A_4 = \sum_{k=1}^4 \sigma_k \vu_k \vv_k^{\tr}\text{.}\) Calculate the relative error in approximating \(A\) by \(A_4\text{.}\) What does this tell us about how much information \(A_4\) contains about \(A\text{?}\) Why?
The first step in compressing an image is to digitize the image. There are many ways to do this and we will consider one of the simplest ways and only work with gray-scale images, with the scale from 0 (black) to 255 (white). A digital image can be created by taking a small grid of squares (called pixels) and coloring each pixel with some shade of gray. The resolution of this grid is a measure of how many pixels are used per square inch. As an example, consider the 16 by 16 pixel picture of a flower shown in Figure 30.1.

To store this image pixel by pixel would require \(16 \times 16 = 256\) units of storage space (1 for each pixel). If we let \(M\) be the matrix whose \(i,j\)th entry is the scale of the \(i,j\)th pixel, then \(M\) is the matrix
Recall that if \(U \Sigma V^{\tr}\) is a singular value decomposition for \(M\text{,}\) then we can also write \(M\) in the form
given in (29.2). For this \(M\text{,}\) the singular values are approximately
Notice that some of these singular values are very small compared to others. As in Preview Activity 30.1, the terms with the largest singular values contain most of the information about the matrix. Thus, we shouldn't lose much information if we eliminate the small singular values. In this particular example, the last 4 singular values are significantly smaller than the rest. If we let
then we should expect the image determined by \(M_{12}\) to be close to the image made by \(M\text{.}\) The two images are presented side by side in Figure 30.2.

This small example illustrates the general idea. Suppose we had a satellite image that was \(1000 \times 1000\) pixels and we let \(M\) represent this image. If we have a singular value decomposition of this image \(M\text{,}\) say
if the rank of \(M\) is large, it is likely that many of the singular values will be very small. If we only keep \(s\) of the singular values, we can approximate \(M\) by
and store the image with only the vectors \(\sigma_1 \vu_1\text{,}\) \(\sigma_2 \vu_2\text{,}\) \(\ldots\text{,}\) \(\sigma_{s}\vu_s\text{,}\) \(\vv_1\text{,}\) \(\vv_1\text{,}\) \(\ldots\text{,}\) \(\vv_s\text{.}\) For example, if we only need 10 of the singular values of a satellite image (\(s = 10\)), then we can store the satellite image with only 20 vectors in \(\R^{1000}\) or with \(20 \times 1000 = 20,000\) numbers instead of \(1000 \times 1000 = 1,000,000\) numbers.
A similar process can be used to denoise data. 52
Subsection Calculating the Error in Approximating an Image
In the context where a matrix represents an image, the operator aspect of the matrix is irrelevant — we are only interested in the matrix as a holder of information. In this situation, we think of an \(m \times n\) matrix as simply a long vector in \(\R^{mn}\) where we have folded the data into a rectangular array. If we are interested in determining the error in approximating an image by a compressed image, it makes sense to use the standard norm in \(\R^{mn}\) to determine length and distance. This leads to what is called the Frobenius norm of a matrix. The Frobenius norm \(||M||_F\) of an \(m \times n\) matrix \(M = [m_{ij}]\) is
There is a natural corresponding inner product on the set of \(m \times n\) matrices (called the Frobenius product) defined by
where \(A = [a_{ij}]\) and \(B = [b_{ij}]\) are \(m \times n\) matrices. Note that
If an \(m \times n\) matrix \(M\) of rank \(r\) has a singular value decomposition \(M = U \Sigma V^{\tr}\text{,}\) we have seen that we can write \(M\) as an outer product
where the \(\vu_i\) are the columns of \(U\) and the \(\vv_j\) the columns of \(V\text{.}\) Each of the products \(\vu_i \vv_i^{\tr}\) is an \(m \times n\) matrix. Since the columns of \(\vu_i \vv_i^{\tr}\) are all scalar multiples of \(\vu_i\text{,}\) the matrix \(\vu_i \vv_i^{\tr}\) is a rank 1 matrix. So (30.3) expresses \(M\) as a sum of rank 1 matrices. Moreover, if we let \(\vx\) and \(\vw\) be \(m \times 1\) vectors and let \(\vy\) and \(\vz\) be \(n \times 1\) vectors with \(\vy = [y_1 \ y_2 \ \ldots \ y_n]^{\tr}\) and \(\vz = [z_1 \ z_2 \ \ldots \ z_n]^{\tr}\text{,}\) then
Using the vectors from the singular value decomposition of \(M\) as in (30.3) we see that
It follows that
Activity 30.2.
Verify (30.4) that \(||M||_F^2 = \sum \sigma_i^2\text{.}\)
When we used the singular value decomposition to approximate the image defined by \(M\text{,}\) we replaced \(M\) with a matrix of the form
We call \(M_k\) the rank \(k\) approximation to \(M\text{.}\) Notice that the outer product expansion in (30.5) is in fact a singular value decomposition for \(M_k\text{.}\) The error \(E_k\) in approximating \(M\) with \(M_k\) is
Once again, notice that (30.6) is a singular value decomposition for \(E_k\text{.}\) We define the relative error in approximating \(M\) with \(M_k\) as
Now (30.4) shows that
In applications, we often want to retain a certain degree of accuracy in our approximations and this error term can help us accomplish that.
In our flower example, the singular values of \(M\) are given in (30.2). The relative error in approximating \(M\) with \(M_{12}\) is
Errors (rounded to 4 decimal places) for approximating \(M\) with some of the \(M_k\) are shown in Table 30.3
| \(k\) | 10 | 9 | 8 | 7 | 6 |
| \(\frac{||E_k||}{||M||}\) | 0.0070 | 0.0146 | 0.0252 | 0.0413 | 0.06426 |
| \(k\) | 5 | 4 | 3 | 2 | 1 |
| \(\frac{||E_k||}{||M||}\) | 0.0918 | 0.1231 | 0.1590 | 0.201 | 0.2460 |
Activity 30.3.
Let \(M\) represent the flower image.
(a)
Find the relative errors in approximating \(M\) by \(M_{13}\) and \(M_{14}\text{.}\) You may use the fact that \(\sqrt{\sum_{i=1}^{16} \sigma_i^2} \approx 3102.0679\text{.}\)
(b)
About how much of the information in the image is contained in the rank 1 approximation? Explain.
Subsection The Condition Number of a Matrix
A singular value decomposition for a matrix \(A\) can tell us a lot about how difficult it is to accurately solve a system \(A \vx = \vb\text{.}\) Solutions to systems of linear equations can be very sensitive to rounding as the next exercise demonstrates.
Activity 30.4.
Find the solution to each of the systems.
(a)
\(\left[ \begin{array}{cc} 1.0000\amp 1.0000 \\ 1.0000\amp 1.0005 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 2.0000 \\ 2.0050 \end{array} \right]\)
(b)
\(\left[ \begin{array}{cc} 1.000\amp 1.000 \\ 1.000\amp 1.001 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 2.000 \\ 2.005 \end{array} \right]\)
Notice that a simple rounding in the \((2,2)\) entry of the coefficient matrix led to a significantly different solution. If there are rounding errors at any stage of the Gaussian elimination process, they can be compounded by further row operations. This is an important problem since computers can only approximate irrational numbers with rational numbers and so rounding can be critical. Finding ways of dealing with these kinds of errors is an area of on-going research in numerical linear algebra. This problem is given a name.
Definition 30.4.
A matrix \(A\) is ill-conditioned if relatively small changes in any entries of \(A\) can produce significant changes in solutions to the system \(A\vx = \vb\text{.}\)
A matrix that is not ill-conditioned is said to be well-conditioned. Since small changes in entries of ill-conditioned matrices can lead to large errors in computations, it is an important problem in linear algebra to have a way to measure how ill-conditioned a matrix is. This idea will ultimately lead us to the condition number of a matrix.
Suppose we want to solve the system \(A \vx = \vb\text{,}\) where \(A\) is an invertible matrix. Activity 30.4 illustrates that if \(A\) is really close to being singular, then small changes in the entries of \(A\) can have significant effects on the solution to the system. So the system can be very hard to solve accurately if \(A\) is close to singular. It is important to have a sense of how “good” we can expect any calculated solution to be. Suppose we think we solve the system \(A \vx = \vb\) but, through rounding error in our calculation of \(A\text{,}\) get a solution \(\vx'\) so that \(A \vx' = \vb'\text{,}\) where \(\vb'\) is not exactly \(\vb\text{.}\) Let \(\Delta \vx\) be the error in our calculated solution and \(\Delta \vb\) the difference between \(\vb'\) and \(\vb\text{.}\) We would like to know how large the error \(||\Delta \vx||\) can be. But this isn't exactly the right question. We could scale everything to make \(||\Delta \vx||\) as large as we want. What we really need is a measure of the relative error \(\frac{||\Delta \vx||}{||\vx||}\text{,}\) or how big the error is compared to \(||\vx||\) itself. More specifically, we want to know how large the relative error in \(\Delta \vx\) is compared to the relative error in \(\Delta \vb\text{.}\) In other words, we want to know how good the relative error in \(\Delta \vb\) is as a predictor of the relative error in \(\Delta \vx\) (we may have some control over the relative error in \(\Delta \vb\text{,}\) perhaps by keeping more significant digits). So we want know if there is a best constant \(C\) such that
This best constant \(C\) is the condition number — a measure of how well the relative error in \(\Delta \vb\) predicts the relative error in \(\Delta \vx\text{.}\) How can we find \(C\text{?}\)
Since \(A \vx' = \vb'\) we have
Distributing on the left and using the fact that \(A\vx = \vb\) gives us
We return for a moment to the operator norm of a matrix. This is an appropriate norm to use here since we are considering \(A\) to be a transformation. Recall that if \(A\) is an \(m \times n\) matrix, we defined the operator norm of \(A\) to be
One important property that the norm has is that if the product \(AB\) is defined, then
To see why, notice that
Now \(\frac{||A(B\vx)||}{||B\vx||} \leq ||A||\) and \(\frac{||B\vx||}{||\vx||} \leq ||B||\) by the definition of the norm, so we conclude that
for every \(\vx\text{.}\) Thus,
Now we can find the condition number. From \(A \Delta \vx = \Delta \vb\) we have
so
Similarly, \(\vb = A\vx\) implies that \(||\vb|| \leq ||A|| \ ||\vx||\) or
Combining (30.8) and (30.9) gives
This constant \(||A^{-1}|| \ ||A||\) is the best bound and so is called the condition number of \(A\text{.}\)
Definition 30.5.
The condition number of an invertible matrix \(A\) is the number \(||A^{-1}|| \ ||A||\text{.}\)
How does a singular value decomposition tell us about the condition number of a matrix? Recall that the maximum value of \(||A\vx||\) for \(\vx\) on the unit \(n\)-sphere is \(\sigma_1\text{.}\) So \(||A|| = \sigma_1\text{.}\) If \(A\) is an invertible matrix and \(A = U \Sigma V^{\tr}\) is a singular value decomposition for \(A\text{,}\) then
where
Now \(V \Sigma^{-1} U^{\tr}\) is a singular value decomposition for \(A^{-1}\) with the diagonal entries in reverse order, so
Therefore, the condition number of \(A\) is
Activity 30.5.
Let \(A = \left[ \begin{array}{cc} 1.0000\amp 1.0000 \\ 1.0000\amp 1.0005 \end{array} \right]\text{.}\) A computer algebra system gives the singular values of \(A\) as 2.00025003124999934 and 0.000249968750000509660. What is the condition number of \(A\text{.}\) What does that tell us about \(A\text{?}\) Does this seem reasonable given the result of Activity 30.4?
Activity 30.6.
(a)
What is the smallest the condition number of a matrix can be? Find an entire class of matrices with this smallest condition number.
(b)
What is the condition number of an orthogonal matrix? Why does this make sense?
If \(P\) is an orthogonal matrix, what is \(||P \vx||\) for any vector \(\vx\text{?}\) What does this make \(||P||\text{?}\)
(c)
What is the condition number of an invertible symmetric matrix in terms of its eigenvalues?
(d)
Why do we not define the condition number of a non-invertible matrix? If we did, what would the condition number have to be? Why?
Subsection Pseudoinverses
Not every matrix is invertible, so we cannot always solve a matrix equation \(A \vx = \vb\text{.}\) However, every matrix has a pseudoinverse \(A^+\) that acts something like an inverse. Even when we can't solve a matrix equation \(A \vx = \vb\) because \(\vb\) isn't in \(\Col A\text{,}\) we can use the pseudoinverse of \(A\) to “solve” the equation \(A \vx = \vb\) with the “solution” \(A^+ \vb\text{.}\) While not an exact solution, \(A^+ \vb\) turns out to be the best approximation to a solution in the least squares sense. We will use the singular value decomposition to find the pseudoinverse of a matrix.
Preview Activity 30.7.
Let \(A = \left[\begin{array}{ccc} 1\amp 1\amp 0\\ 0\amp 1\amp 1 \end{array} \right]\text{.}\) The singular value decomposition of \(A\) is \(U \Sigma V^{\tr}\) where
(a)
Explain why \(A\) is not an invertible matrix.
(b)
Explain why the matrices \(U\) and \(V\) are invertible. How are \(U^{-1}\) and \(V^{-1}\) related to \(U^{\tr}\) and \(V^{\tr}\text{?}\)
(c)
Recall that one property of invertible matrices is that the inverse of a product of invertible matrices is the product of the inverses in the reverse order. If \(A\) were invertible, then \(A^{-1}\) would be \(\left(U \Sigma V^{\tr}\right)^{-1} = V \Sigma^{-1} U^{\tr}\text{.}\) Even though \(U\) and \(V\) are invertible, the matrix \(\Sigma\) is not. But \(\Sigma\) does contain non-zero eigenvalues that have reciprocals, so consider the matrix \(\Sigma^+ = \left[ \begin{array}{cc} \frac{1}{\sqrt{3}}\amp 0 \\ 0\amp 1 \\ 0\amp 0 \end{array} \right]\text{.}\) Calculate the products \(\Sigma \Sigma^+\) and \(\Sigma^+ \Sigma\text{.}\) How are the results similar to that obtained with a matrix inverse?
(d)
The only matrix in the singular value decomposition of \(A\) that is not invertible is \(\Sigma\text{.}\) But the matrix \(\Sigma^{+}\) acts somewhat like an inverse of \(\Sigma\text{,}\) so let us define \(A^+\) as \(V \Sigma^+ U^{\tr}\text{.}\) Now we explore a few properties of the matrix \(A^{+}\text{.}\)
(i)
Calculate \(AA^+\) and \(A^+A\) for \(A = \left[\begin{array}{ccc} 1\amp 1\amp 0\\ 0\amp 1\amp 1 \end{array} \right]\text{.}\) What do you notice?
(ii)
Calculate \(A^+AA^+\) and \(AA^+A\) for \(A = \left[\begin{array}{ccc} 1\amp 1\amp 0\\ 0\amp 1\amp 1 \end{array} \right]\text{.}\) What do you notice?
Only some square matrices have inverses. However, every matrix has a pseudoinverse. A pseudoinverse \(A^{+}\) of a matrix \(A\) provides something like an inverse when a matrix doesn't have an inverse. Pseudoinverses are useful to approximate solutions to linear systems. If \(A\) is invertible, then the equation \(A \vx = \vb\) has the solution \(\vx = A^{-1}\vb\text{,}\) but when \(A\) is not invertible and \(\vb\) is not in \(\Col A\text{,}\) then the equation \(A \vx = \vb\) has no solution. In the invertible case of an \(n \times n\) matrix \(A\text{,}\) there is a matrix \(B\) so that \(AB = BA = I_n\text{.}\) This also implies that \(BAB = B\) and \(ABA = A\text{.}\) To mimic this situation when \(A\) is not invertible, we search for a matrix \(A^+\) (a pseudoinverse of \(A\)) so that \(AA^+A = A\) and \(A^+AA^+ = A^+\text{,}\) as we saw in Preview Activity 30.7. Then it turns out that \(A^+\) acts something like an inverse for \(A\text{.}\) In this case, we approximate the solution to \(A \vx = \vb\) by \(\vx^* = A^+\vb\text{,}\) and we will see that the vector \(A\vx^* = AA^+\vb\) turns out to be the vector in \(\Col A\) that is closest to \(\vb\) in the least squares sense.
A reasonable question to ask is how we can find a pseudoinverse of a matrix \(A\text{.}\) A singular value decomposition provides an answer to this question. If \(A\) is an invertible \(n \times n\) matrix, then 0 is not an eigenvalue of \(A\text{.}\) As a result, in the singular value decomposition \(U \Sigma V^{\tr}\) of \(A\text{,}\) the matrix \(\Sigma\) is an invertible matrix (note that \(U\text{,}\) \(\Sigma\text{,}\) and \(V\) are all \(n \times n\) matrices in this case). So
where
In this case, \(V \Sigma^{-1} U^{\tr}\) is a singular value decomposition for \(A^{-1}\text{.}\)
To understand in general how a pseudoinverse is found, let \(A\) be an \(m \times n\) matrix with \(m \neq n\text{,}\) or an \(n \times n\) with rank less than \(n\text{.}\) In these cases \(A\) does not have an inverse. But as in Preview Activity 30.7, a singular value decomposition provides a pseudoinverse \(A^+\) for \(A\text{.}\) Let \(U \Sigma V^{\tr}\) be a singular value decomposition of an \(m \times n\) matrix \(A\) of rank \(r\text{,}\) with
The matrices \(U\) and \(V\) are invertible, but the matrix \(\Sigma\) is not if \(A\) is not invertible. If we let \(\Sigma^+\) be the \(n \times m\) matrix defined by
then \(\Sigma^{+}\) will act much like an inverse of \(\Sigma\) might. In fact, it is not difficult to see that
where \(\Sigma\Sigma^{+}\) is an \(m \times m\) matrix and \(\Sigma^{+}\Sigma\) is an \(n \times n\) matrix.
The matrix
is a pseudoinverse of \(A\text{.}\)
Activity 30.8.
(a)
Find the pseudoinverse \(A^+\) of \(A = \left[ \begin{array}{rc} 0\amp 5\\ 4\amp 3 \\ -2\amp 1 \end{array} \right]\text{.}\) Use the singular value decomposition \(U \Sigma V^{\tr}\) of \(A\text{,}\) where
(b)
The vector \(\vb = \left[ \begin{array}{c} 0\\0\\1 \end{array} \right]\) is not in \(\Col A\text{.}\) The vector \(\vx^* = A^+ \vb\) is an approximation to a solution of \(A \vx = \vb\text{,}\) and \(AA^+\vb\) is in \(\Col A\text{.}\) Find \(A\vx^*\) and determine how far \(A\vx^*\) is from \(\vb\text{.}\)
Pseudoinverses satisfy several properties that are similar to those of inverses. For example, we had an example in Preview Activity 30.7 where \(AA^{+}A = A\) and \(A^+AA^+ = A^+\text{.}\) That \(A^+\) always satisfies these properties is the subject of the next activity.
Activity 30.9.
Let \(A\) be an \(m \times n\) matrix with singular value decomposition \(U \Sigma V^{\tr}\text{.}\) Let \(A^{+}\) be defined as in (30.10).
(a)
Show that \(AA^{+}A = A\text{.}\)
(b)
Show that \(A^{+}AA^{+} = A^{+}\text{.}\)
Activity 30.9 shows that \(A^{+}\) satisfies properties that are similar to those of an inverse of \(A\text{.}\) In fact, \(A^{+}\) satisfies several other properties (that together can be used as defining properties) as stated in the next theorem. The conditions of Theorem 30.6 are called the Penrose or Moore-Penrose conditions. 53 Verification of the remaining parts of this theorem are left for the exercises.
Theorem 30.6. The Moore-Penrose Conditions.
A pseudoinverse of a matrix \(A\) is a matrix \(A^+\) that satisfies the following properties.
\(\displaystyle AA^{+}A = A\)
\(\displaystyle A^{+}AA^{+} = A^{+}\)
\(\displaystyle (AA^{+})^{\tr} = AA^{+}\)
\(\displaystyle (A^{+}A)^{\tr} = A^{+}A\)
Also, there is a unique matrix \(A^+\) that satisfies these properties. The verification of this property is left to the exercises.
Subsection Least Squares Approximations
The pseudoinverse of a matrix is also connected to least squares solutions of linear systems as we encountered in Section 24. Recall from Section 24, that if the columns of \(A\) are linearly independent, then the least squares solution to \(A\vx = \vb\) is \(\vx = \left(A^{\tr}A\right)^{-1}A^{\tr} \vb\text{.}\) In this section we will see how to use a pseudoinverse to solve a least squares problem, and verify that if the columns of \(A\) are linearly dependent, then \(\left(A^{\tr}A\right)^{-1}A^{\tr}\) is in fact the pseudoinverse of \(A\text{.}\)
Let \(U \Sigma V^{\tr}\) be a singular value decomposition for an \(m \times n\) matrix \(A\) of rank \(r\text{.}\) Then the columns of
form an orthonormal basis for \(\R^m\) and \(\{\vu_1, \vu_2, \ldots, \vu_r\}\) is a basis for \(\Col A\text{.}\) Remember from Section 25 that if \(\vb\) is any vector in \(\R^m\text{,}\) then
is the least squares approximation of the vector \(\vb\) by a vector in \(\Col A\text{.}\) We can extend this sum to all of columns of \(U\) as
It follows that
where
Now, if \(\vz = A^{+} \vb\text{,}\) then
and hence the vector \(A \vz = AA^+ \vb\) is the vector \(A\vx\) in \(\Col A\) that minimizes \(||A \vx - \vb||\text{.}\) Thus, \(A\vz\) is in actuality the least squares approximation to \(\vb\text{.}\) So a singular value decomposition allows us to construct the pseudoinverse of a matrix \(A\) and then directly solve the least squares problem.
If the columns of \(A\) are linearly independent, then we do not need to use an SVD to find the pseudoinverse, as the next activity illustrates.
Activity 30.10.
Having to calculate eigenvalues and eigenvectors for a matrix to produce a singular value decomposition to find pseudoinverse can be computationally intense. As we demonstrate in this activity, the process is easier if the columns of \(A\) are linearly independent. More specifically, we will prove the following theorem.
Theorem 30.7.
If the columns of a matrix \(A\) are linearly independent, then \(A^{+} = \left(A^{\tr}A\right)^{-1}A^{\tr}\text{.}\)
To see how, suppose that \(A\) is an \(m \times n\) matrix with linearly independent columns.
(a)
Given that the columns of \(A\) are linearly independent, what must be the relationship between \(n\) and \(m\text{?}\)
(b)
Since the columns of \(A\) are linearly independent, it follows that \(A^{\tr}A\) is invertible (see Activity 26.4). So the eigenvalues of \(A^{\tr}A\) are all non-zero. Let \(\sigma_1\text{,}\) \(\sigma_2\text{,}\) \(\ldots\text{,}\) \(\sigma_r\) be the singular values of \(A\text{.}\) How is \(r\) related to \(n\text{,}\) and what do \(\Sigma\) and \(\Sigma^{+}\) look like?
(c)
Let us now investigate the form of the invertible matrix \(A^{\tr}A\) (note that neither \(A\) nor \(A^{\tr}\) is necessarily invertible). If a singular value decomposition of \(A\) is \(U \Sigma V^{\tr}\text{,}\) show that
(d)
Let \(\lambda_i = \sigma_i^2\) for \(i\) from 1 to \(n\text{.}\) It is straightforward to see that \(\Sigma^{\tr} \Sigma\) is an \(n \times n\) diagonal matrix \(D\text{,}\) where
Then \((A^{\tr}A)^{-1} = VD^{-1}V^{\tr}\text{.}\) Recall that \(A^{+} = V \Sigma^{+} U^{\tr}\text{,}\) so to relate \(A^{\tr}A\) to \(A^{+}\) we need a product that is equal to \(\Sigma^{+}\text{.}\) Explain why
(e)
Complete the activity by showing that
Therefore, to calculate \(A^{+}\) and solve a least squares problem, Theorem 30.7 shows that as long as the columns of \(A\) are linearly independent, we can avoid using a singular value decomposition of \(A\) in finding \(A^{+}\text{.}\)
Subsection Examples
What follows are worked examples that use the concepts from this section.
Example 30.8.
Let
The eigenvalues of \(A^{\tr}A\) are \(\lambda_1 = 144\text{,}\) \(\lambda_2 = 36\text{,}\) and \(\lambda_3=0\) with corresponding eigenvectors
In addition,
(a)
Find orthogonal matrices \(U\) and \(V\text{,}\) and the matrix \(\Sigma\text{,}\) so that \(U \Sigma V^{\tr}\) is a singular value decomposition of \(A\text{.}\)
Solution.
Normalizing the eigenvectors \(\vw_1\text{,}\) \(\vw_2\text{,}\) and \(\vw_3\) to normal eigenvectors \(\vv_1\text{,}\) \(\vv_2\text{,}\) and \(\vv_3\text{,}\) respectively, gives us an orthogonal matrix
Now \(A \vv_i = A \frac{\vw_i}{||\vw_i||} = \frac{1}{||\vw_i||} A \vw_i\text{,}\) so normalizing the vectors \(A \vw_1\) and \(A \vw_2\) gives us vectors
that are the first two columns of our matrix \(U\text{.}\) Given that \(U\) is a \(4 \times 4\) matrix, we need to find two other vectors orthogonal to \(\vu_1\) and \(\vu_2\) that will combine with \(\vu_1\) and \(\vu_2\) to form an orthogonal basis for \(\R^4\text{.}\) Letting \(\vz_1 = [1 \ 1 \ 1 \ 1]^{\tr}\text{,}\) \(\vz_2 = [1 \ -1 \ -1 \ 1]^{\tr}\text{,}\) \(\vz_3 = [1 \ 0 \ 0 \ 0]^{\tr}\text{,}\) and \(\vz_4 = [0 \ 1 \ 0 \ 1]^{\tr}\text{,}\) a computer algebra system shows that the reduced row echelon form of the matrix \([\vz_1 \ \vz_2 \ \vz_3 \ \vz_4]\) is \(I_4\text{,}\) so that vectors \(\vz_1\text{,}\) \(\vz_2\text{,}\) \(\vz_3\text{,}\) \(\vz_4\) are linearly independent. Letting \(\vw_1 = \vz_1\) and \(\vw_2 = \vz_2\text{,}\) the Gram-Schmidt process shows that the set \(\{\vw_1, \vw_2, \vw_3, \vw_4\}\) is an orthogonal basis for \(\R^4\text{,}\) where \(\vw_3 = \frac{1}{4} [2 \ 0 \ 0 \ -2]^{\tr}\) and (using \([1 \ 0 \ 0 \ -1]^{\tr}\) for \(\vw_3\)) \(\vw_4 = \frac{1}{4} [0 \ 2 \ -2 \ 0]^{\tr}\text{.}\) The set \(\{\vu_1, \vu_2, \vu_3, \vu_4\}\) where \(\vu_1 = \frac{1}{2}[1 \ 1 \ 1 \ 1]^{\tr}\text{,}\) \(\vu_2 = \frac{1}{2}[1 \ -1 \ -1 \ 1]^{\tr}\text{,}\) \(\vu_3 = \frac{1}{\sqrt{2}}[1 \ 0 \ 0 \ -1]^{\tr}\) and \(\vu_4 = \frac{1}{\sqrt{2}}[0 \ 1 \ -1 \ 0]^{\tr}\) is an orthonormal basis for \(\R^4\) and we can let
The singular values of \(A\) are \(\sigma_1 = \sqrt{\lambda_1} = 12\) and \(\sigma_2 = \sqrt{\lambda_2} = 6\text{,}\) and so
Therefore, a singular value decomposition of \(A\) is \(U \Sigma V^{\tr}\) of
(b)
Determine the best rank 1 approximation to \(A\text{.}\) Give an appropriate numerical estimate as to how good this approximation is to \(A\text{.}\)
Solution.
The outer product decomposition of \(A\) is
So the rank one approximation to \(A\) is
The error in approximating \(A\) with this rank one approximation is
(c)
Find the pseudoinverse \(A^+\) of \(A\text{.}\)
Solution.
Given that \(A = U \Sigma V^{\tr}\text{,}\) we use the pseudoinverse \(\Sigma^+\) of \(\Sigma\) to find the pseudoinverse \(A^+\) of \(A\) by
Now
so
(d)
Let \(\vb = \left[ \begin{array}{c} 1\\0\\1\\0 \end{array} \right]^{\tr}\text{.}\) Does the matrix equation
have a solution? If so, find the solution. If not, find the best approximation you can to a solution to this matrix equation.
Solution.
Augmenting \(A\) with \(\vb\) and row reducing shows that
so \(\vb\) is not in \(\Col A\) and the equation \(A\vx = \vb\) has no solution. However, the best approximation to a solution to \(A \vx = \vb\) is found using the pseudoinverse \(A^+\) of \(A\text{.}\) That best solution is
(e)
Use the orthogonal basis \(\{\frac{1}{2}[1 \ 1 \ 1 \ 1]^{\tr}, \frac{1}{2}[1 \ -1 \ -1 \ 1]^{\tr}\}\) of \(\Col A\) to find the projection of \(\vb\) onto \(\Col A\text{.}\) Compare to your solution in part (c).
Solution.
The rank of \(A\) is 2 and an orthonormal basis for \(\Col A\) is \(\{\vu_1, \vu_2\}\text{,}\) where \(\vu_1 = \frac{1}{2}[1 \ 1 \ 1 \ 1]^{\tr}\) and \(\vu_2 = \frac{1}{2}[1 \ -1 \ -1 \ 1]^{\tr}\text{.}\) So
as expected from part (c).
Example 30.9.
Table 30.10 shows the per capita debt in the U.S. in from 2014 to 2019 (source statistica.com 54 ).
| Year | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 |
| Debt | 55905 | 56513 | 60505 | 62174 | 65697 | 69064 |
(a)
Set up a linear system of the form \(A \vx = \vb\) whose least squares solution provides a linear fit to the data.
Solution.
A linear approximation \(f(x) = a_0 + a_1x\) to the system would satisfy the equation \(A \vx = \vb\text{,}\) where \(A = \left[ \begin{array}{cc} 1\amp 2014 \\ 1\amp 2015 \\ 1\amp 2016 \\ 1\amp 2017 \\ 1\amp 2018 \\ 1\amp 2019 \end{array} \right]\text{,}\) \(\vx = \left[ \begin{array}{c} a_0 \\ a_1 \end{array} \right]\text{,}\) and \(\vb = \left[ \begin{array}{c} 55905 \\ 56513 \\ 60505 \\ 62174 \\ 65697 \\ 69064 \end{array} \right]\text{.}\)
(b)
Use technology to approximate a singular value decomposition (round to four decimal places). Use this svd to approximate the pseudoinverse of \(A\text{.}\) Then use this pseudoinverse to approximate the least squares linear approximation to the system.
Solution.
Technology shows that a singular value decomposition of \(A\) is approximately \(U \Sigma V^{\tr}\text{,}\) where
Thus, with \(\Sigma^+ = \left[ \begin{array}{cccccc} \frac{1}{4939.3984}\amp 0\amp 0\amp 0\amp 0\amp 0 \\ 0\amp \frac{1}{0.0021}\amp 0\amp 0\amp 0\amp 0 \end{array} \right]\text{,}\) we have that the pseudoinverse of \(A\) is approximately
So our least squares linear approximation is found by
This makes our least squares linear approximation to be (to four decimal places)
(c)
Calculate \(\left(A^{\tr}A\right)^{-1}A^{\tr}\) directly and compare to the pseudoinverse you found in part (b).
Solution.
Calculating \(\left(A^{\tr}A\right)^{-1}A^{\tr}\) gives the same matrix as \(A^+\text{,}\) so we obtain the same linear approximation.
(d)
Use your approximation to estimate the U.S. per capita debt in 2020.
Solution.
The approximate U.S. per capita debt in 2020 is
Subsection Summary
The condition number of an \(m \times n\) matrix \(A\) is the number \(||A^{-1}|| \ ||A||\text{.}\) The condition number provides a measure of how well the relative error in a calculated value \(\Delta \vb\) predicts the relative error in \(\Delta \vx\) when we are trying to solve a system \(A \vx = \vb\text{.}\)
-
A pseudoinverse \(A^{+}\) of a matrix \(A\) can be found through a singular value decomposition. Let \(U \Sigma V^{\tr}\) be a singular value decomposition of an \(m \times n\) matrix \(A\) of rank \(r\text{,}\) with
\begin{equation*} \Sigma = \left[ \begin{array}{ccccc|c} \sigma_1\amp \amp \amp \amp \amp \\ \amp \sigma_2\amp \amp 0\amp \amp \\ \amp \amp \sigma_3\amp \amp \amp 0 \\ \amp 0 \amp \amp \ddots \amp \amp \\ \amp \amp \amp \amp \sigma_r \\ \hline \amp \amp 0\amp \amp \amp 0 \end{array} \right] \end{equation*}If \(\Sigma^+\) is the \(n \times m\) matrix defined by
\begin{equation*} \Sigma^{+} = \left[ \begin{array}{ccccc|c} \frac{1}{\sigma_1}\amp \amp \amp \amp \amp \\ \amp \frac{1}{\sigma_2}\amp \amp 0\amp \amp \\ \amp \amp \frac{1}{\sigma_3}\amp \amp \amp 0 \\ \amp 0 \amp \amp \ddots \amp \amp \\ \amp \amp \amp \amp \frac{1}{\sigma_r} \\ \hline \amp \amp 0\amp \amp \amp 0 \end{array} \right]\text{,} \end{equation*}then \(A^{+} = V\Sigma^{+}U^{\tr}\text{.}\)
A pseudoinverse \(A^{+}\) of a matrix \(A\) acts like an inverse for \(A\text{.}\) So if we can't solve a matrix equation \(A \vx = \vb\) because \(\vb\) isn't in \(\Col A\text{,}\) we can use the pseudoinverse of \(A\) to “solve” the equation \(A \vx = \vb\) with the “solution” \(A^+ \vb\text{.}\) While not an exact solution, \(A^+ \vb\) turns out to be the best approximation to a solution in the least squares sense.
Exercises Exercises
1.
Let \(A = \left[ \begin{array}{rcc} 20\amp 4\amp 32 \\ -4\amp 4\amp 2 \\ 35\amp 22\amp 26 \end{array} \right]\text{.}\) Then \(A\) has singular value decomposition \(U \Sigma V^{\tr}\) , where
(a)
What are the singular values of \(A\text{?}\)
(b)
Write the outer product decomposition of \(A\text{.}\)
(c)
Find the best rank 1 approximation to \(A\text{.}\) What is the relative error in approximating \(A\) by this rank 1 matrix?
(d)
Find the best rank 2 approximation to \(A\text{.}\) What is the relative error in approximating \(A\) by this rank 2 matrix?
2.
Let \(A = \left[ \begin{array}{ccrr} 861\amp 3969\amp 70\amp 140 \\ 3969\amp 861\amp 70\amp 140 \\ 3969\amp 861\amp -70\amp -140 \\ 861\amp 3969\amp -70\amp -140 \end{array} \right]\text{.}\)
(a)
Find a singular value decomposition for \(A\text{.}\)
(b)
What are the singular values of \(A\text{?}\)
(c)
Write the outer product decomposition of \(A\text{.}\)
(d)
Find the best rank 1, 2, and 3 approximations to \(A\text{.}\) How much information about \(A\) does each of these approximations contain?
3.
Assume that the number of feet traveled by a batted baseball at various angles in degrees (all hit at the same bat speed) is given in Table 30.11.
| Angle | \(10^{\circ}\) | \(20^{\circ}\) | \(30^{\circ}\) | \(40^{\circ}\) | \(50^{\circ}\) | \(60^{\circ}\) |
| Distance | 116 | 190 | 254 | 285 | 270 | 230 |
(a)
Plot the data and explain why a quadratic function is likely a better fit to the data than a linear function.
(b)
Find the least squares quadratic approximation to this data. Plot the quadratic function on same axes as your data.
(c)
At what angle (or angles), to the nearest degree, must a player bat the ball in order for the ball to travel a distance of 220 feet?
4.
How close can a matrix be to being non-invertible? We explore that idea in this exercise. Let \(A = [a_{ij}]\) be the \(n \times n\) upper triangular matrix with 1s along the diagonal and with every other entry being \(-1\text{.}\)
(a)
What is \(\det(A)\text{?}\) What are the eigenvalues of \(A\text{?}\) Is \(A\) invertible?
(b)
Let \(B = [b_{ij}]\) be the \(n \times n\) matrix so that \(b_{n1} = -\frac{1}{2^{n-2}}\) and \(b_{ij} = a_{ij}\) for all other \(i\) and \(j\text{.}\)
(i)
For the matrix \(B\) with \(n=3\text{,}\) show that the equation \(B \vx = \vzero\) has a non-trivial solution. Find one non-trivial solution.
(ii)
For the matrix \(B\) with \(n=4\text{,}\) show that the equation \(B \vx = \vzero\) has a non-trivial solution. Find one non-trivial solution.
(iii)
Use the pattern established in parts (i.) and (ii.) to find a non-trivial solution to the equation \(B \vx = \vzero\) for an arbitrary value of \(n\text{.}\) Be sure to verify that you have a solution. Is \(B\) invertible?
For any positive integer \(m\text{,}\) the sum \(1+\sum_{k=0}^{m-1} 2^k\) is the partial sum of a geometric series with ratio \(2\) and so \(1+\sum_{k=0}^{m-1} 2^k = 1+\frac{1-2^m}{1-2} = 2^m\text{.}\)
(iv)
Explain why \(B\) is not an invertible matrix. Notice that \(A\) and \(B\) differ by a single entry, and that \(A\) is invertible and \(B\) is not. Let us examine how close \(A\) is to \(B\text{.}\) Calculate \(|| A - B ||_F\text{?}\) What happens to \(||A - B||_F\) as \(n\) goes to infinity? How close can an invertible matrix be to becoming non-invertible?
5.
Let \(A = \left[ \begin{array}{crr} 1\amp 0\amp 0 \\ 0\amp 1\amp -1 \\ 0\amp -1\amp 1 \end{array} \right]\text{.}\) In this exercise we find a matrix \(B\) so that \(B^2 = A\text{,}\) that is, find a square root of the matrix \(A\text{.}\)
(a)
Find the eigenvalues and corresponding eigenvectors for \(A\) and \(A^{\tr}A\text{.}\) Explain what you see.
(b)
Find a matrix \(V\) that orthogonally diagonalizes \(A^{\tr}A\text{.}\)
(c)
Exercise 8 in Section 29 shows if \(U \Sigma V^{\tr}\) is a singular value decomposition for a symmetric matrix \(A\text{,}\) then so is \(V \Sigma V^{\tr}\text{.}\) Recall that \(A^n = \left(V \Sigma V^{\tr}\right)^n = V \Sigma^n V^{\tr}\) for any positive integer \(n\text{.}\) We can exploit this idea to define \(\sqrt{A}\) to be the matrix
where \(\Sigma^{1/2}\) is the matrix whose diagonal entries are the square roots of the corresponding entries of \(\Sigma\text{.}\) Let \(B = \sqrt{A}\text{.}\) Calculate \(B\) and show that \(B^2 = A\text{.}\)
(d)
Why was it important that \(A\) be a symmetric matrix for this process to work, and what had to be true about the eigenvalues of \(A\) for this to work?
(e)
Can you extend the process in this exercise to find a cube root of \(A\text{?}\)
6.
Let \(A\) be an \(m \times n\) matrix with singular value decomposition \(U \Sigma V^{\tr}\text{.}\) Let \(A^{+}\) be defined as in (30.10). In this exercise we prove the remaining parts of Theorem 30.6.
(a)
Show that \((AA^{+})^{\tr} = AA^{+}\text{.}\)
\(\Sigma \Sigma^+\) is a symmetric matrix.
(b)
Show that \((A^{+}A)^{\tr} = A^{+}A\text{.}\)
7.
In this exercise we show that the pseudoinverse of a matrix is the unique matrix that satisfies the Moore-Penrose conditions. Let \(A\) be an \(m \times n\) matrix with singular value decomposition \(U \Sigma V^{\tr}\) and pseudoinverse \(X = V\Sigma^{+}U^{\tr}\text{.}\) To show that \(A^{+}\) is the unique matrix that satisfies the Moore-Penrose conditions, suppose that there is another matrix \(Y\) that also satisfies the Moore-Penrose conditions.
(a)
Show that \(X = YAX\text{.}\)
Use the fact that \(X= XAX\text{.}\)
(b)
Show that \(Y = YAX\text{.}\)
Use the fact that \(Y= YAY\text{.}\)
(c)
How do the results of parts (a) and (b) show that \(A^{+}\) is the unique matrix satisfying the Moore-Penrose conditions?
Compare the results of (a) and (b).
8.
Find the pseudoinverse of the \(m \times n\) zero matrix \(A=0\text{.}\) Explain the conclusion.
9.
In all of the examples that we have done finding a singular value decomposition of a matrix, it has been the case (though we haven't mentioned it), that if \(A\) is an \(m \times n\) matrix, then \(\rank(A) = \rank\left(A^{\tr}A\right)\text{.}\) Prove this result.
10.
Label each of the following statements as True or False. Provide justification for your response.
(a) True/False.
A matrix has a pseudo-inverse if and only if the matrix is singular.
(b) True/False.
The pseudoinverse of an invertible matrix \(A\) is the matrix \(A^{-1}\text{.}\)
(c) True/False.
If the columns of \(A\) are linearly dependent, then there is no least squares solution to \(A\vx = \vb\text{.}\)
(d) True/False.
If the columns of \(A\) are linearly independent, then there is a unique least squares solution to \(A\vx = \vb\text{.}\)
(e) True/False.
If \(T\) is the matrix transformation defined by a matrix \(A\) and \(S\) is the matrix transformation defined by \(A^{+}\text{,}\) then \(T\) and \(S\) are inverse transformations.
Subsection Project: GPS and Least Squares
In this project we discuss some of the details about how the GPS works. The idea is based on intersections of spheres. To build a basic understanding of the system, we begin with a 2-dimensional example.
Project Activity 30.11.
Suppose that there are three base stations \(A\text{,}\) \(B\text{,}\) and \(C\) in \(\R^2\) that can send and receive signals from your mobile phone. Assume that \(A\) is located at point \((-1,-2)\text{,}\) \(B\) at point \((36,5)\text{,}\) and \(C\) at point \((16,35)\text{.}\) Also assume that your mobile phone location is point \((x,y)\text{.}\) Based on the time that it takes to receive the signals from the three base stations, it can be determined that your distance to base station \(A\) is \(28\) km, your distance to base station \(B\) is \(26\) km, and your distance to base station \(C\) is \(14\) km using a coordinate system with measurements in kilometers based on a reference point chosen to be \((0,0)\text{.}\) Due to limitations on the measurement equipment, these measurements all contain some unknown error which we will denote as \(z\text{.}\) The goal is to determine your location in \(\R^2\) based on this information.
If the distance readings were accurate, then the point \((x,y)\) would lie on the circle centered at \(A\) of radius \(29\text{.}\) The distance from \((x,y)\) to base station \(A\) can be represented in two different ways: \(28\) km and \(\sqrt{(x+1)^2 + (y+2)^2}\text{.}\) However, there is some error in the measurements (due to the receiver clock and satellite clocks not being snychronized), so we really have
where \(z\) is the error. Similarly, \((x,y)\) must also satisfy
and
(a)
Explain how these three equations can be written in the equivalent form

(b)
If all measurements were accurate, your position would be at the intersection of the circles centered at \(A\) with radius \(28\) km, centered at \(B\) with radius \(26\) km, and centered at \(C\) with radius \(14\) km as shown in Figure 30.12. Even though the figure might seem to imply it, because of the error in the measurements the three circles do not intersect in one point. So instead, we want to find the best estimate of a point of intersection that we can. The system of equations (30.11), (30.12), and (30.13) is non-linear and can be difficult to solve, if it even has a solution. To approximate a solution, we can linearize the system. To do this, show that if we subtract corresponding sides of equation (30.11) from (30.12) and expand both sides, we can obtain the linear equation
in the unknowns \(x\text{,}\) \(y\text{,}\) and \(z\text{.}\)
(c)
Repeat the process in part (b), subtracting (30.11) from (30.13) and show that we can obtain the linear equation
in \(x\text{,}\) \(y\text{,}\) and \(z\text{.}\)
(d)
We have reduced our system of three non-linear equations to the system
of two linear equations in the unknowns \(x\text{,}\) \(y\text{,}\) and \(z\text{.}\) Use technology to find a pseudoinverse of the coefficient matrix of this system. Use the pseudoinverse to find the least squares solution to this system. Does your solution correspond to an approximate point of intersection of the three circles?
Project Activity 30.11 provides the basic idea behind GPS. Suppose you receive a signal from a GPS satellite. The transmission from satellite \(i\) provides four pieces of information — a location \((x_i,y_i,z_i)\) and a time stamp \(t_i\) according to the satellite's atomic clock. The time stamp allows the calculation of the distance between you and the \(i\)th satellite. The transmission travel time is calculated by subtracting the current time on the GPS receiver from the satellite's time stamp. Distance is then found by multiplying the transmission travel time by the rate, which is the speed of light \(c=299792.458\) km/s. 55 So distance is found as \(c(t_i-d)\text{,}\) where \(d\) is the time at the receiver. This signal places your location within in a sphere of that radius from the center of the satellite. If you receive a signal at the same time from two satellites, then your position is at the intersection of two spheres. As can be seen at left in Figure 30.13, that intersection is a circle. So your position has been narrowed quite a bit. Now if you receive simultaneous signals from three spheres, your position is narrowed to the intersection of three spheres, or two points as shown at right in Figure 30.13. So if we could receive perfect information from three satellites, then your location would be exactly determined.
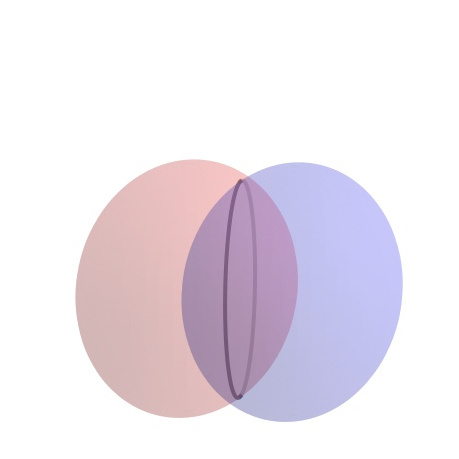
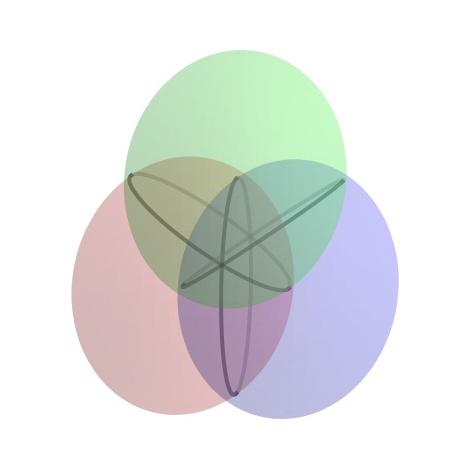
There is a problem with the above analysis — calculating the distances. These distances are determined by the time it takes for the signal to travel from the satellite to the GPS receiver. The times are measured by the clocks in the satellites and the clocks in the receivers. Since the GPS receiver clock is unlikely to be perfectly synchronized with the satellite clock, the distance calculations are not perfect. In addition, the rate at which the signal travels can change as the signal moves through the ionosphere and the troposphere. As a result, the calculated distance measurements are not exact, and are referred to as pseudoranges. In our calculations we need to factor in the error related to the time discrepancy and other factors. We will incorporate these errors into our measure of \(d\) and treat \(d\) as an unknown. (Of course, this is all more complicated that is presented here, but this provides the general idea.)
To ensure accuracy, the GPS uses signals from four satellites. Assume a satellite is positioned at point \((x_1,y_1,z_1)\) at a distance \(d_1\) from the GPS receiver located at point \((x,y,z)\text{.}\) The distance can also be measured in two ways: as
and as \(c(t_1-d)\text{.}\) So
Again, we are treating \(d\) as an unknown, so this equation has the four unknowns \(x\text{,}\) \(y\text{,}\) \(z\text{,}\) and \(d\text{.}\) Using signals from four satellites produces the system of equations
Project Activity 30.12.
The system of equations (30.14), (30.15), (30.16), and (30.17) is a non-linear system and is difficult to solve, if it even has a solution. We want a method that will provide at least an approximate solution as well as apply if we use more than four satellites. We choose a reference node (say \((x_1, y_1, z_1)\)) and make calculations relative to that node as we did in Project Activity 30.11.
(a)
First square both sides of the equations (30.14), (30.15), (30.16), and (30.17) to remove the roots. Then subtract corresponding sides of the new first equation (involving \((x_1,y_1,z_1)\)) from the new second equation (involving \((x_2,y_2,z_2)\)) to show that we can obtain the linear equation
where \(h_i = x_i^2 + y_i^2 + z_i^2\text{.}\) (Note that the unknowns are \(x\text{,}\) \(y\text{,}\) \(z\text{,}\) and \(d\) — all other quantities are known.)
(b)
Use the result of part (a) to write a linear system that can be obtained by subtracting the first equation from the third and fourth equations as well.
(c)
The linearizations from part (b) determine a system \(A \vx = \vb\) of linear equations. Identify \(A\text{,}\) \(\vx\text{,}\) and \(\vb\text{.}\) Then explain how we can approximate a best solution to this system in the least squares sense.
We conclude this project with a final note. At times a GPS receiver may only be able to receive signals from three satellites. In these situations, the receiver can substitute the surface of the Earth as a fourth sphere and continue the computation.
http://www2.imm.dtu.dk/~pch/Projekter/tsvd.html, “The SVD [singular value decomposition] has also applications in digital signal processing, e.g., as a method for noise reduction. The central idea is to let a matrix \(A\) represent the noisy signal, compute the SVD, and then discard small singular values of \(A\text{.}\) It can be shown that the small singular values mainly represent the noise, and thus the rank-\(k\) matrix \(A_k\) represents a filtered signal with less noise.”statista.com/statistics/203064/national-debt-of-the-united-states-per-capita/